Use utility mapping algorithms to help implement cost-utility analyses
Categories:
This below section renders a vignette article from the youthu library. You can use the following links to:
- view the vignette on the library website (adds useful hyperlinks to code blocks)
- view the source file from that article, and;
- edit its contents (requires a GitHub account).
This vignette illustrates the rationale for and practical decision-making utility of youthu’s QALYs prediction workflow. Note, this example is illustrated with fake data and should not be used to inform decision-making.
Motivation
The main motivation behind the youthu package is to extend the types of economic analysis that can be undertaken with both single group (e.g. pilot study, health service records) and matched groups (e.g. trial) longitudinal datasets that do not include measures of health utility. This article focuses on its application to matched group datasets.
Example dataset
First, we must first import our data. In this example we will use a fake dataset.
ds_tb <- make_fake_ds_two()
#> Joining with `by = join_by(fkClientID, study_arm_chr)`
Our dataset includes 268 matched comparisons, with each comparison containing baseline and follow-up records for one intervention arm participant and one control arm participant. The first few records are as follows.
| fkClientID | round | date_psx | duration_prd | PHQ9 | SOFAS | costs_dbl | study_arm_chr | match_idx_int |
|---|---|---|---|---|---|---|---|---|
| Participant_20 | Baseline | 2023-07-04 | 0S | 16 | 41 | 301.1868 | Intervention | 1 |
| Participant_593 | Baseline | 2023-05-11 | 0S | 19 | 43 | 259.3190 | Control | 1 |
| Participant_593 | Follow-up | 2023-11-02 | 175d 0H 0M 0S | 16 | 65 | 1290.4220 | Control | 1 |
| Participant_20 | Follow-up | 2023-12-29 | 178d 0H 0M 0S | 15 | 74 | 1787.4242 | Intervention | 1 |
| Participant_259 | Baseline | 2023-08-29 | 0S | 19 | 39 | 311.0018 | Control | 2 |
| Participant_962 | Baseline | 2023-10-11 | 0S | 10 | 45 | 276.2181 | Intervention | 2 |
This dataset contains features that make it possible to use in conjunction with youthu’s economic analysis functions. These requirements are described in the vignette about finding and using models compatible models to predict QALYs;
The dataset also contains a cost variable, which is a requirement for most, though not all, of the economic analyses that can be undertaken with youthu.
Limitations of datasets without measures of health utility
A notable omission from the dataset is any measure of utility. This omission means that, in the absence of using mapping algorithms such as those included with youthu, the most feasible types of economic evaluation to apply to this dataset would likely be cost-consequence analysis (where a synopsis of the differences in a range of measures are presented alongside cost differences) and cost-effectiveness analysis (where a summary statistic - the incremental cost-effectiveness ratio or ICER - is calculated by dividing differences in costs by differences in a single outcome measure).
These types of economic analyses can be relatively simple to interpret if either the intervention or control arm is simultaneously cheaper and more effective across all included outcome measures. However, these conditions don’t hold in our sample data.
summary((ds_tb %>% dplyr::filter(study_arm_chr == "Control" & round == "Baseline"))[5:6])
#> PHQ9 SOFAS
#> Min. : 0.0 Min. :39.00
#> 1st Qu.: 7.0 1st Qu.:60.00
#> Median :12.0 Median :66.00
#> Mean :10.9 Mean :66.13
#> 3rd Qu.:15.0 3rd Qu.:72.00
#> Max. :19.0 Max. :89.00
summary((ds_tb %>% dplyr::filter(study_arm_chr == "Control" & round == "Follow-up"))[5:7])
#> PHQ9 SOFAS costs_dbl
#> Min. : 0.000 Min. :39.00 Min. : 889.9
#> 1st Qu.: 4.000 1st Qu.:64.00 1st Qu.:1321.1
#> Median : 8.000 Median :71.00 Median :1486.7
#> Mean : 8.493 Mean :70.65 Mean :1489.0
#> 3rd Qu.:13.000 3rd Qu.:77.00 3rd Qu.:1627.0
#> Max. :27.000 Max. :98.00 Max. :2216.5
summary((ds_tb %>% dplyr::filter(study_arm_chr == "Intervention" & round == "Baseline"))[5:6])
#> PHQ9 SOFAS
#> Min. : 0.00 Min. :36.00
#> 1st Qu.: 7.00 1st Qu.:61.00
#> Median :11.00 Median :67.00
#> Mean :10.81 Mean :66.74
#> 3rd Qu.:15.00 3rd Qu.:72.25
#> Max. :19.00 Max. :88.00
summary((ds_tb %>% dplyr::filter(study_arm_chr == "Intervention" & round == "Follow-up"))[5:7])
#> PHQ9 SOFAS costs_dbl
#> Min. : 0.000 Min. :40 Min. : 923.4
#> 1st Qu.: 2.000 1st Qu.:60 1st Qu.:1625.6
#> Median : 6.500 Median :68 Median :1777.3
#> Mean : 6.851 Mean :68 Mean :1807.8
#> 3rd Qu.:11.000 3rd Qu.:77 3rd Qu.:1996.0
#> Max. :25.000 Max. :93 Max. :2872.7
The pattern of results summarised above create some significant barriers to meaningfully interpreting economic evaluations that are based on cost-consequence or cost-effectiveness analysis:
-
A cost-effectiveness analysis in which change in PHQ-9 was the benefit measure would be difficult to interpret as the Intervention arm is both more effective and more costly, which begs the question is it worth paying the extra dollars for this improvement? Also - would a judgment of cost-effectiveness remain the same if the study had measured a slightly different incremental benefit or recorded change over a longer or shorter time horizon? It is likely that there is no commonly used value for money benchmark for improvements measured in PHQ-9, nor is there any time weighting associated with the measure. Furthermore, if the potential funding for the intervention is from a budget that is allocated to non-depressive illnesses (e.g. physical health), results from a cost-effectiveness analysis using PHQ-9 as its benefit measure are not readily comparable with economic evaluations of interventions from other illness groups using different benefit measures that are potentially competing for the same scarce funding.
-
A cost consequence analyses that summarised the differences in costs with the differences in changes in PHQ-9 and SOFAS score would be difficult to interpret because while the intervention is more effective than control for improvements measured on PHQ-9 (where lower scores are better), the control group is superior if benefits are based on functioning improvements as measured by SOFAS scores (where higher scores are better). The lack of any formal weighting for how to trade off clinical symptoms and functioning means that interpretation of this analysis will be highly subjective and likely to change across potential decision makers.
These types of short-comings can be significantly addressed by undertaking cost-utility analyses (CUAs) as:
- they use a measure of benefit - the Quality Adjusted Life Year (QALY) - that captures multiple domains of health, weighted by time and population preferences in a single index measure that can be applied across health conditions;
- there are published benchmark willingness to pay values for QALYs that are routinely used by decision makers in many countries to make ICER statistics readily interpretable in the context of health budget allocation.
The rest of this article demonstrates how youthu functions can be used to undertake CUA based analyses on the type of data we have just profiled.
Using youthu in a cost-utility analysis workflow
Predict adolescent AQoL-6D health utility
Our first step is to identify which youthu models we will use to predict adolescent AQoL-6D and apply these models to our data. This step was explained in more detail in another vignette article about finding and using transfer to utility models, so will be dealt with briefly here.
We ingest metadata about the mapping models we plan to use. NOTE: This is a temporary step that is required due to the metadata file not being in the study online repository. This code will cease to work once the metadata file has been moved from its temporary location to the study dataset. We will perform this task when an associated manuscript exits its current review process.
mdl_meta_data_ls <- ingest(Ready4useRepos(gh_repo_1L_chr = "ready4-dev/youthu", gh_tag_1L_chr = "v0.0.0.91125"), fls_to_ingest_chr = c("mdl_meta_data_ls"), metadata_1L_lgl = F)We now make sure that our dataset can be used as a prediction dataset in conjunction with the model we intend using.
predn_ds_ls <- make_predn_metadata_ls(ds_tb,
cmprsn_groups_chr = c("Intervention", "Control"),
cmprsn_var_nm_1L_chr = "study_arm_chr",
costs_var_nm_1L_chr = "costs_dbl",
id_var_nm_1L_chr = "fkClientID",
mdl_meta_data_ls = mdl_meta_data_ls,
msrmnt_date_var_nm_1L_chr = "date_psx",
round_var_nm_1L_chr = "round",
round_bl_val_1L_chr = "Baseline",
utl_var_nm_1L_chr = "AQoL6D_HU",
mdls_lup = get_mdls_lup(utility_type_chr = "AQoL-6D",
mdl_predrs_in_ds_chr = c("PHQ9 total score",
"SOFAS total score"),
ttu_dv_nms_chr = "TTU"),
mdl_nm_1L_chr = "PHQ9_SOFAS_1_OLS_CLL")We now use our preferred model to predict health utility from the measures in our dataset.
ds_tb <- add_utl_predn(ds_tb,
predn_ds_ls = predn_ds_ls) %>%
dplyr::select(fkClientID, round, study_arm_chr, date_psx, duration_prd, dplyr::everything())
#> Joining with `by = join_by(fkClientID, round)`
Calculate QALYs
Next we combine the health utility data with the interval between measurement data to calculate QALYs and add them to the dataset.
ds_tb <- ds_tb %>% add_qalys_to_ds(predn_ds_ls = predn_ds_ls,
include_predrs_1L_lgl = T,
reshape_1L_lgl = T)| fkClientID | study_arm_chr | match_idx_int | date_psx_Baseline | date_psx_Follow-up | duration_prd_Baseline | duration_prd_Follow-up | costs_dbl_Baseline | costs_dbl_Follow-up | PHQ9_Baseline | PHQ9_Follow-up | SOFAS_Baseline | SOFAS_Follow-up | AQoL6D_HU_Baseline | AQoL6D_HU_Follow-up | PHQ9_change_dbl_Baseline | PHQ9_change_dbl_Follow-up | SOFAS_change_dbl_Baseline | SOFAS_change_dbl_Follow-up | AQoL6D_HU_change_dbl_Baseline | AQoL6D_HU_change_dbl_Follow-up | qalys_dbl_Baseline | qalys_dbl_Follow-up |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Participant_10 | Control | 243 | 2023-04-19 | 2023-10-13 | 0S | 177d 0H 0M 0S | 647.9386 | 1696.235 | 8 | 10 | 61 | 64 | 0.7597988 | 0.6079774 | 0 | 2 | 0 | 3 | 0 | -0.1518214 | 0 | 0.3314119 |
| Participant_1000 | Control | 191 | 2023-06-15 | 2023-12-16 | 0S | 184d 0H 0M 0S | 428.9205 | 1619.037 | 4 | 2 | 63 | 82 | 0.8459579 | 0.7688131 | 0 | -2 | 0 | 19 | 0 | -0.0771448 | 0 | 0.4067322 |
| Participant_1001 | Intervention | 230 | 2023-05-10 | 2023-11-05 | 0S | 179d 0H 0M 0S | 429.3703 | 1844.219 | 10 | 14 | 59 | 72 | 0.6138300 | 0.8607305 | 0 | 4 | 0 | 13 | 0 | 0.2469005 | 0 | 0.3613228 |
| Participant_1003 | Intervention | 115 | 2023-06-08 | 2023-12-07 | 0S | 182d 0H 0M 0S | 395.1637 | 1537.365 | 9 | 0 | 71 | 81 | 0.5808015 | 0.9315788 | 0 | -9 | 0 | 10 | 0 | 0.3507773 | 0 | 0.3768011 |
| Participant_1005 | Intervention | 183 | 2023-09-09 | 2024-03-13 | 0S | 186d 0H 0M 0S | 402.9910 | 1826.511 | 17 | 0 | 78 | 88 | 0.5460607 | 0.9593811 | 0 | -17 | 0 | 10 | 0 | 0.4133204 | 0 | 0.3833158 |
| Participant_1006 | Intervention | 219 | 2023-10-05 | 2024-04-01 | 0S | 179d 0H 0M 0S | 534.2285 | 2401.478 | 9 | 14 | 75 | 73 | 0.7239490 | 0.5885972 | 0 | 5 | 0 | -2 | 0 | -0.1353518 | 0 | 0.3216232 |
Analyse results
Now we can run the main economic analysis. This is implemented by the make_hlth_ec_smry function, which first bootstraps the dataset (implemented by the boot function from the boot package) before passing the mean values for costs and QALYs from each bootstrap sample to with bcea function of the BCEA package to calculate a range of health economic statistics. For this example we pass a value of 50,000 for the willingness to pay parameter, as this is the dollar amount commonly used in Australia as a benchmark for the value of a QALY.
Note, for this illustrative example we only request 1000 bootstrap iterations - in practice this number may be higher.
he_smry_ls <- ds_tb %>% make_hlth_ec_smry(predn_ds_ls = predn_ds_ls,
wtp_dbl = 50000,
bootstrap_iters_1L_int = 1000L)
#> Warning: There was 1 warning in `dplyr::summarise()`.
#> ℹ In argument: `dplyr::across(.fns = mean)`.
#> Caused by warning:
#> ! Using `across()` without supplying `.cols` was deprecated in dplyr 1.1.0.
#> ℹ Please supply `.cols` instead.
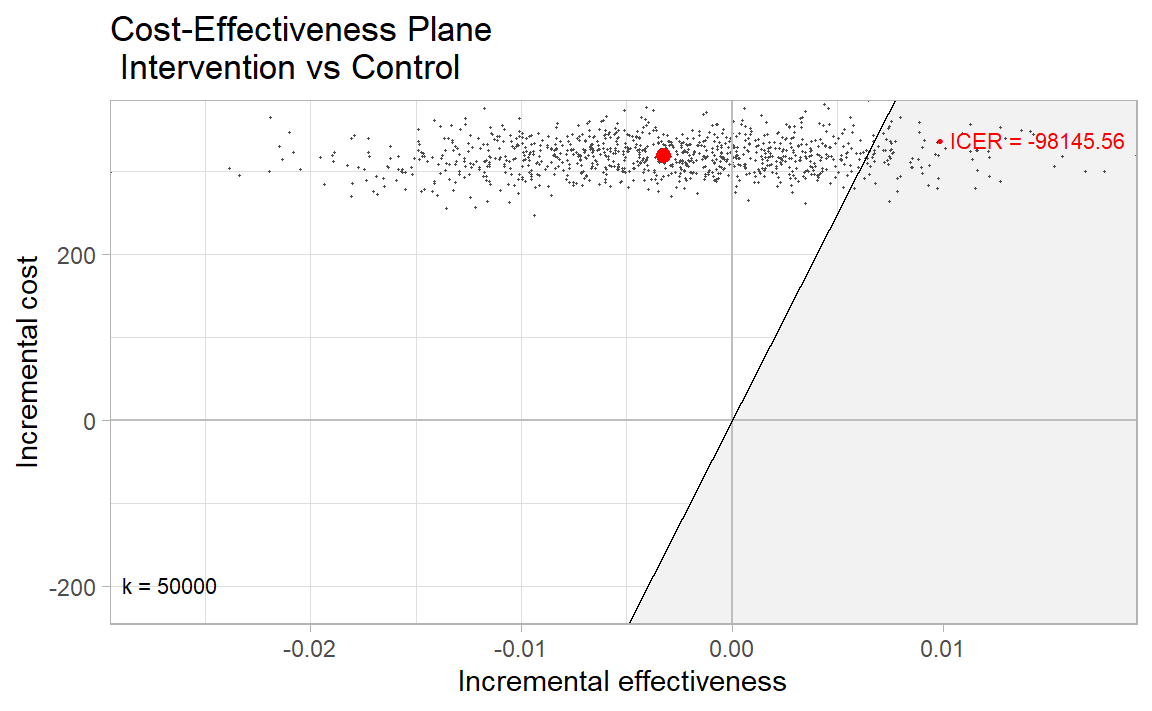
As part of the output of the make_hlth_ec_smry function is a BCEA object, we can use the BCEA package to produce a number of graphical summaries of economic results. One of the most important is the production of a cost-effectiveness plane. This plot highlights that, with an ICER of $-98,145.56, less than half of the bootstrapped iteration incremental cost and QALY pairs fall within the zone of cost-effectiveness (green). In fact, at the cost-effectiveness threshold we supplied, the results suggest there is a 8% probability that the intervention is cost-effective.
BCEA::ceplane.plot(he_smry_ls$ce_res_ls, wtp =50000, graph = "ggplot2", theme = ggplot2::theme_light())